NVIDIA Unveils Groq 3 LPU: The $20 Billion Inference Chip That Redefines AI Computing
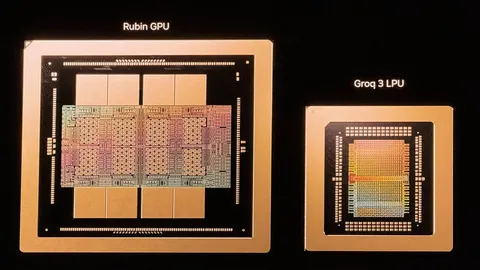
NVIDIA unveiled the Groq 3 LPU at GTC 2026, the inference-only chip from its $20 billion Groq acquisition. With SRAM-based architecture delivering 7x bandwidth and 35x power efficiency over GPUs, this chip signals the dawn of a bifurcated AI computing era: GPUs for training, LPUs for inference.
In December 2025, NVIDIA acquired inference chip startup Groq for $20 billion. When the company bought networking firm Mellanox for $6.9 billion in 2019, the industry was puzzled. But Mellanox's technology became the backbone of data center connectivity, completing the final puzzle piece of NVIDIA's AI dominance. That's why Jensen Huang called this latest acquisition a 'Mellanox Moment.' And at the GTC 2026 keynote, the result of that bet -- the Groq 3 LPU -- was unveiled for the first time.
What If SRAM Replaces HBM?

At the heart of the Groq 3 LPU is its memory architecture. Unlike traditional GPUs that rely on HBM (High Bandwidth Memory), Groq 3 integrates SRAM directly into the chip. Each chip packs 500MB of SRAM and delivers 1.2 petaflops of inference performance at 8-bit precision.
The real difference shows up in bandwidth. Groq 3's SRAM bandwidth reaches 150 TB/s. Considering that the HBM in NVIDIA's next-generation Vera Rubin GPU delivers 22 TB/s, that's roughly a 7x advantage. In inference workloads, memory bandwidth equals speed -- how fast you can read and write data directly determines token generation speed.
"Low latency and high throughput are enemies of each other. That's why we need separate machines for both." -- Jensen Huang, GTC 2026 Keynote
256 LPUs in a Single Rack

While single-chip performance is impressive, the Groq 3's true potential emerges at rack scale. The Groq 3 LPX rack integrates 256 LPUs into a single rack, delivering 128GB of total SRAM and 40 PB/s of internal bandwidth. At GTC 2026, this system was displayed alongside the Vera Rubin rack.
| Specification | Groq 3 LPU | Vera Rubin GPU |
|---|---|---|
| Memory Type | SRAM | HBM |
| Per-Chip Memory | 500MB | Tens of GB |
| Memory Bandwidth | 150 TB/s | 22 TB/s |
| Optimized For | Inference (low latency) | Training (high throughput) |
| Token/Watt Efficiency | 35x over GPU | Baseline |
NVIDIA placing its latest GPU and LPU on the same stage is deeply significant. It's effectively a self-declaration that the era of solving both AI workloads -- training and inference -- with a single architecture is coming to an end.
GPUs for Training, LPUs for Inference: The Logic of Bifurcation
Why can't GPUs handle everything? AI training involves repeatedly processing massive datasets to adjust model weights. High throughput is the key here -- parallel computation across tens of terabytes of parameters demands large-capacity HBM and powerful compute units.
Inference, on the other hand, uses trained models to generate responses in real time. Every moment a chatbot crafts an answer, a coding agent generates code, or an AI NPC delivers dialogue in a game -- that's inference. What matters here isn't throughput but latency. Users want responses as fast as possible. These two demands are fundamentally at odds. That's the backdrop to Jensen Huang's declaration that 'the inference inflection has arrived.'
SRAM is the hardware answer to this problem. Positioned closer to the chip than HBM, it offers dramatically lower access latency. The trade-off is smaller capacity and higher cost -- but inference workloads don't need as much memory as training. Groq 3's all-in bet on SRAM is the result of choosing a design optimized for a specific problem: inference.
The Changes Real-Time AI Services Will Feel

NVIDIA claims the Groq 3 LPU achieves 35x the token-per-watt efficiency of the Vera Rubin GPU. Whether this number holds up in actual production environments remains to be seen, but the direction is clear: far more inference requests can be processed with the same power budget.
The real-world impact is broad. AI chatbot response times speed up. Coding agents generate code near-instantly. AI-powered search returns results faster. In gaming, this enables real-time AI NPC dialogue generation, inference-based in-game content creation, and improved cloud gaming responsiveness. As inference latency shrinks, AI evolves from 'a tool you wait for' to 'an instant companion.'
Why NVIDIA Is Disrupting Itself
What's fascinating is that NVIDIA itself acknowledged the limitations of GPUs and presented an alternative. Until now, NVIDIA's strategy was to dominate both training and inference with a single GPU architecture. Now it's effectively declaring that inference needs its own dedicated chip.
But this isn't destruction -- it's expansion. The inference market is growing faster than training. As AI services proliferate, training happens once but inference occurs every moment. Had NVIDIA clung to GPUs alone, companies like Google, Microsoft, and the original Groq would have carved out the inference market. Spending $20 billion to acquire Groq was an aggressive defensive strategy to preempt the inference market as well.
Just as the Mellanox acquisition filled the missing puzzle piece of data center networking, the Groq acquisition fills the missing piece of inference. NVIDIA is now the only company that owns the full AI computing stack from training to inference. With both GPU and LPU blades in hand, how NVIDIA defines the new order of AI computing will be closely watched -- and March 2026 may well be recorded as a turning point in the history of AI semiconductors.



