Same-Day Showdown: Claude Opus 4.6 vs GPT-5.3-Codex Simultaneous Launch

Anthropic's Opus 4.6 and OpenAI's GPT-5.3-Codex launched simultaneously on Feb 5. The Terminal-Bench top score changed hands within 30 minutes — a full breakdown of the AI coding agent war.
On February 5, 2026, the two titans of the AI industry—Anthropic and OpenAI—simultaneously unveiled their next-generation models on the same day. Anthropic released Opus 4.6 while OpenAI launched GPT-5.3-Codex, forming a direct head-to-head confrontation over dominance in the AI agent era.
Claude Opus 4.6 — A Premium General-Purpose Model That 'Thinks Longer and Deeper'


Opus 4.6 significantly enhances the coding capabilities of its predecessor Opus 4.5 while delivering dominant performance in general knowledge tasks. It's the first Opus model to support 1 million token context (beta), with maximum output doubled to 128K tokens.
The most notable change is 'Adaptive Thinking.' Previously, extended thinking was a binary on/off choice, but now the model autonomously determines whether to think deeply or respond quickly based on context. Additionally, reasoning effort levels (low/medium/high/max) allow developers to fine-tune the balance between intelligence, speed, and cost.
Benchmark results are impressive. It set the top score on Terminal-Bench 2.0 (an AI coding agent evaluation), and ranked first among all models in composite reasoning tests. In real-world knowledge task evaluations, it led OpenAI's GPT-5.2 by approximately 144 Elo points. In long-context retrieval, it scored 76%, vastly outperforming Sonnet 4.5's 18.5%.
Claude Code added an 'Agent Teams' feature in preview, enabling multiple agents to collaborate in parallel on large-scale tasks like code reviews. Pricing was maintained at $5 per million input tokens and $25 per million output tokens, the same as Opus 4.5.
GPT-5.3-Codex — The Coding Agent That 'Built Itself'

On the same day, OpenAI released GPT-5.3-Codex with the striking title of 'the first model to participate in its own training.' OpenAI revealed that early versions of GPT-5.3-Codex were used to debug its own training, manage deployments, and diagnose test results.
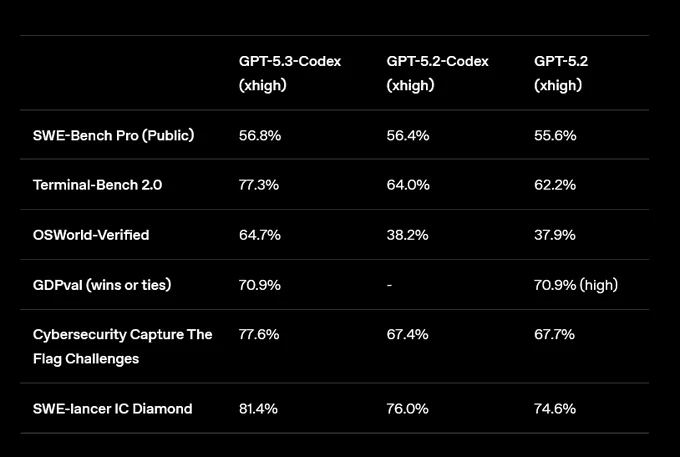
Performance-wise, GPT-5.3-Codex achieved an industry-best 56.8% on SWE-Bench Pro (a real-world software engineering evaluation) and 77.3% on Terminal-Bench 2.0. It scored 64.7% on OSWorld-Verified (productivity tasks in visual desktop environments), a major leap from GPT-5.2's 37.9%.
Versatility beyond coding was also emphasized. It supports presentation creation, spreadsheet analysis, and data processing pipeline construction, showing GPT-5.2-level performance across 44 professional knowledge task evaluations. A 25% speed improvement over its predecessor is also noteworthy.
Counterfire 30 Minutes Later — The Timing War
After Anthropic unveiled Opus 4.6, OpenAI responded with GPT-5.3-Codex just 30 minutes later. The timing was too precise to be coincidental. Industry observers believe OpenAI anticipated Anthropic's announcement and prepared a counter-launch strategy. In fact, OpenAI's Codex app had already been released on February 2, and 5.3-Codex was a model upgrade on top of it.
The most dramatic moment unfolded on the Terminal-Bench 2.0 leaderboard. The previous #1 was Factory's Droid + GPT-5.2 combination at 64.9%. Opus 4.6 claimed the top spot at 65.4% (max reasoning), edging ahead by just 0.5 percentage points. But merely 30 minutes later, GPT-5.3-Codex posted 77.3%, overtaking it by roughly 12 percentage points. Opus 4.6's record lasted only 30 minutes. However, since both companies used different execution environments (harnesses), direct model-to-model performance comparison has its limitations.
Head-to-Head Benchmark Comparison
Comparing the figures released by both companies: Terminal-Bench 2.0: Opus 4.6 65.4% vs GPT-5.3-Codex 77.3%. Interestingly, both chose different SWE-Bench evaluation versions. Anthropic reported Verified (80.84%) and Multilingual (77.83%), while OpenAI highlighted Pro (56.8%). The current SWE-Bench Pro leaderboard has Opus 4.5 at #1 with 45.89%, so if Opus 4.6's Pro score is released, the landscape could shift again. Both companies strategically showcased evaluation criteria favorable to their own models.
In real-world knowledge task evaluations, Opus 4.6 led GPT-5.2 by approximately 144 Elo points. GPT-5.3-Codex achieved a 70.9% win rate in the same evaluation, maintaining GPT-5.2-level performance. In desktop environment productivity task evaluations, GPT-5.3-Codex dominated at 64.7%. In cybersecurity CTF evaluations, GPT-5.3-Codex scored 77.6%, while Opus 4.6 used the expression 'industry-leading' instead of providing exact figures.
In long-context tasks, Opus 4.6 held a clear advantage. It scored 76% in retrieving key information from 1 million token-scale documents, vastly outperforming Sonnet 4.5's 18.5%. Opus 4.6 supports 1 million token context (beta) and 128K output tokens, while GPT-5.3-Codex opted for context compression to manage long sessions.
The AI Agent War Is Just Getting Started
Coincidentally, this simultaneous launch came right after a war of words between the two companies over Super Bowl advertising. The two companies that were trading barbs on social media the day before released their next-generation models at the same time the very next day. Their fierce competition will continue to be the biggest spectacle in the AI industry.
Meanwhile, it's puzzling that GPT-5.3-Codex is explicitly described as a GPT-5.2-based model. Given the '5.3' numbering, some interpret it as closer to a coding agent-specialized fine-tune rather than a fundamental architectural change.