Kimi K2.7 Code: Moonshot Cuts Reasoning 30%
Moonshot AI open-sourced Kimi K2.7 Code, cutting reasoning tokens 30% vs K2.6 while raising coding scores. Weights and API shipped the same day.
Moonshot AI released its Kimi K2.7 Code model on June 12 without a preview period or waitlist. The model weights were published on Hugging Face and the API went live on the same day, establishing it as a fully open-source coding model from launch. The company has described it as its most capable coding model to date.
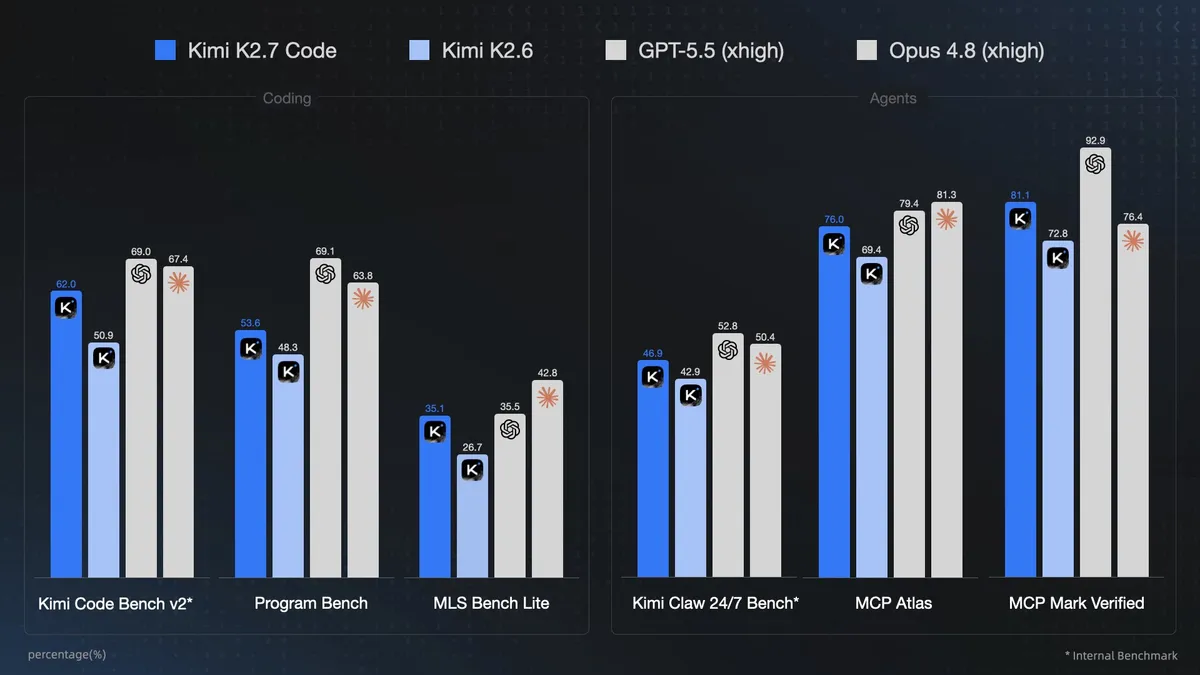
Rather than a benchmark score, the headline figure of the announcement is an efficiency metric. Moonshot AI stated that Kimi K2.7 Code uses approximately 30% fewer reasoning tokens than its predecessor, K2.6, while improving its score on the internal Kimi Code Bench v2 from 50.9 to 62.0, representing a 21.8% relative improvement. The core value proposition of this release is simple: reduced computation delivering superior performance.
Reducing Reasoning Tokens by 30%
Developers who use reasoning-based models for extended coding sessions are familiar with a common inefficiency: a model may consume 3,000 tokens deliberating over a problem that could be addressed with 1,500 tokens. In agent-based workflows involving hundreds of tool calls, this operational overhead translates directly into higher costs.
Kimi K2.7 Code reduces these reasoning tokens by approximately 30% compared to K2.6 while simultaneously increasing task success rates. The model achieved an 11.0% improvement on Program Bench and a 31.5% increase on MLS Bench Lite, while scoring 9.5% and 11.4% higher on the tool-use benchmarks MCP Atlas and MCP Mark Verified, respectively.
| Benchmark | K2.6 | K2.7 Code | Change |
|---|---|---|---|
| Kimi Code Bench v2* | 50.9 | 62.0 | +21.8% |
| Program Bench | 48.3 | 53.6 | +11.0% |
| MLS Bench Lite | 26.7 | 35.1 | +31.5% |
| MCP Atlas | 69.4 | 76.0 | +9.5% |
| MCP Mark Verified | 72.8 | 81.1 | +11.4% |
A key caveat remains: Kimi Code Bench v2 and several other prominent figures are based on Moonshot AI's internal evaluations and lack independent external verification. However, because the model weights are publicly available, developers can download and verify these claims directly.
Same 1T MoE Architecture, Optimized for Coding

For developers planning local deployment, the technical specifications are substantial. Kimi K2.7 Code retains the architecture of K2.6: a 1-trillion-parameter Mixture-of-Experts (MoE) design with 32 billion active parameters per token and a 256K context window. Optimized through quantization-aware training (QAT), the native INT4 version requires a download of approximately 594 GB.
The model lacks a standard, immediate-response mode, operating exclusively in reasoning modes. Moonshot AI designed this constraint intentionally, tailoring the model for long-horizon agent tasks rather than brief queries. The software is released under a modified MIT license, which mandates displaying 'Kimi K2' in the user interface only for commercial products exceeding 100 million monthly active users or $20 million in monthly revenue.
Moonshot AI's data also highlights the model's limitations. Proprietary models like GPT-5.5 and Claude Opus 4.8 continue to lead on Program Bench and MCP Mark Verified. Rather than representing an outright victory, the release demonstrates how open-source alternatives are challenging established proprietary APIs in the June coding-agent standings through efficiency.
An Open-Source Coding Model Priced for Competition
The model's efficiency advantages are reflected directly in its pricing. The official API rates are set at $0.19 per million tokens for cache hits, $0.95 for inputs, and $4.00 for outputs. For extended agent workflows that repeatedly process large system prompts, the low cache-hit price significantly reduces overall operational expenses. Moonshot AI has also announced that a six-times faster high-speed mode will be available soon.
Industry reception has been swift. On the r/LocalLLaMA forum, early feedback suggests that the reduction in redundant reasoning, combined with reliability in long-duration tasks, makes this a highly practical open-source coding agent. Given that Cursor's Composer 2.5 was built on a fine-tuned version of Kimi K2.5, comparisons between the new release and the upstream base model are expected to emerge shortly.
The frequency of Moonshot AI's releases conveys a clear strategic intent. Since introducing the original K2 in July 2025, followed by K2 Thinking, K2.5, and K2.6, the launch of Kimi K2.7 Code marks the company's fifth major model release in less than a year. The open-source community is increasingly challenging closed APIs on unit economics, with this open-source coding model establishing competitive standards for pricing as well as performance.



