Microsoft Eyes DeepSeek to Cut Copilot Costs

Microsoft is weighing self-hosted DeepSeek for Copilot to cut costs, as GLM-5.2, Kimi K2.7 and DeepSeek V4 near frontier quality far more cheaply.
Microsoft is considering integrating China's DeepSeek into parts of its Copilot assistant as a low-cost option. On June 16, Axios reported that the tech giant is weighing a self-hosted variant of DeepSeek V4 for its 'Copilot Cowork' feature, with a potential announcement of a lower-cost model tier expected within weeks.
The primary driver behind Microsoft's potential shift is cost. Copilot Cowork, which relies on autonomous agents to execute multi-step workflows, consumes tokens rapidly during extended tasks. Operating these workloads exclusively on premium frontier models from OpenAI and Anthropic is financially unsustainable under Copilot's current cost structure, which is precisely what is pushing the company toward a cheaper frontier alternative.
Why Copilot is Turning to DeepSeek
The compounding expenses stem from Copilot Cowork's operational design. A single user prompt initiates a chain of model calls as the agent performs searches, edits documents, and verifies results. Because operational costs scale directly with productivity, Microsoft is shifting its pricing strategy from flat-rate subscriptions toward usage-based models.
To address this, Microsoft is pursuing a multi-model strategy. The company is evaluating a version of DeepSeek, refined with additional safety filters to reduce bias, hosted directly within its Azure cloud infrastructure. The deployment would serve as an opt-in option for enterprise customers, with Microsoft assuring that user data remains within the Azure boundary.
The strategy is clear: delegate routine agent tasks to lower-cost models, reserve expensive frontier models for complex reasoning, and reduce Microsoft's near-exclusive reliance on OpenAI. However, as Gizmodo noted, a major U.S. technology company integrating a Chinese-developed model into a flagship product could face political headwinds in Washington.
Chinese Models Closing the Gap with Frontier Models

Microsoft's consideration is supported by the rapid advancement of Chinese AI models over recent months. GLM-5.2, released by Z.ai on June 13, stably processes a 1-million-token context window and achieved a score of 81.0 on the Terminal-Bench 2.1 benchmark. With Claude Opus 4.8 scoring 85.0 on the same evaluation, the performance gap has narrowed to single digits.
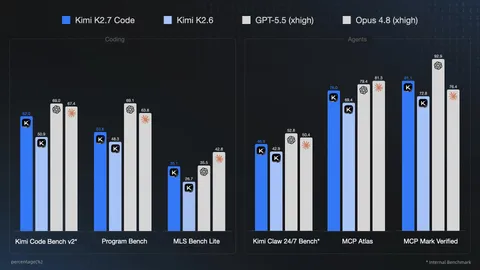
Other Chinese AI models are advancing at a similar pace. Moonshot released its Kimi K2.7 Code model on June 12, reducing reasoning token consumption by 30% compared to its predecessor. Additionally, DeepSeek V4-Pro achieved an accuracy rate in the low 80% range on the SWE-bench Verified benchmark during its April launch. Notably, all three models combine open-weights accessibility with 1-million-token context capacities.
While these benchmarks are vendor-reported and still undergoing independent verification, initial hands-on reviews suggest the claims are credible. In hands-on evaluations of GLM-5.2, the model's coding capabilities received praise, though feedback on pricing structures and stability remained mixed. Nevertheless, positioning these systems as a credible frontier alternative is no longer an exaggeration.
Tenfold Savings on Paper, Fiftyfold in Practice
While performance is competitive, the pricing differential remains the most significant factor. DeepSeek V4-Pro is priced at $0.87 per million output tokens, compared to $25 for Claude Opus 4.8 and $30 for GPT-5.5. At standard list prices, DeepSeek V4-Pro is roughly 29 to 34 times cheaper. Its lighter counterpart, V4-Flash, costs just $0.28 per million output tokens, nearly 90 times less than Claude Opus 4.8.
DeepSeek V4-Pro's operational cost gap is even wider in practice than list prices suggest. DeepSeek maintains a continuous 75% discount, reducing its cached-input rate to $0.003625 per million tokens for repeated prompts. When combined with a tokenizer optimized to consume fewer tokens for code and structured data, analyses indicate that cache-friendly workloads can be up to 50 times cheaper than those on frontier models. Conversely, reports indicate that Claude's newer tokenizer can generate up to 35% more tokens for identical text, further widening the cost disparity.
Consequently, these Chinese AI models are shifting from a cheap frontier alternative to a default candidate for daily operational workflows. The fact that even Microsoft is weighing a frontier alternative from China for its flagship productivity suite is the clearest signal of where the AI market is tilting.



- Axios - Microsoft weighs a lower-cost DeepSeek model for Copilot Cowork
- Gizmodo - Microsoft Mulls China's DeepSeek for Copilot, Probably to Trump's Chagrin
- MarkTechPost - Z.ai Launches GLM-5.2 With a Usable 1M Token Context
- VentureBeat - Kimi K2.7-Code cuts thinking tokens 30%, practitioners say benchmarks don't check out
- Simon Willison - DeepSeek V4