GLM-5.2 Overtakes Gemini 3.5 Flash

Four days after launch, GLM-5.2 hit 51 on the Artificial Analysis Intelligence Index, edging out Gemini 3.5 Flash — the top open-weight score yet.
Four days after Z.ai released the open-weight GLM-5.2 on June 13, the independent benchmarks are rolling in — and the numbers are landing harder than the launch itself.
On the Artificial Analysis Intelligence Index (v4.1), GLM-5.2 (Max) scored 51, edging out Gemini 3.5 Flash (High) — Google's state-of-the-art efficiency model — by a single point. It is the first time an open-weight model has passed the model Google pushes as its efficiency-tier best, and it did so as a free, MIT-licensed download trained exclusively on Huawei hardware.
Detailed Benchmarks Behind the Score
The model's score of 51 on the Artificial Analysis Intelligence Index is a composite of coding, reasoning, knowledge, and agentic capabilities. With this score, GLM-5.2 leads the open-weight field, standing seven points ahead of its closest competitors, MiniMax-M3 (44) and DeepSeek V4-Pro (44), and eleven points above its predecessor, GLM-5.1.
In coding and agentic evaluations, the gap between this open model and the leading closed-source frontier models continues to narrow. According to third-party data compiled by VentureBeat, GLM-5.2 outperforms GPT-5.5 on multiple long-horizon coding tasks at one-sixth the operating cost. The model achieved a score of 62.1 on SWE-bench Pro compared to GPT-5.5's 58.6, and reached 74.4 on the long-horizon FrontierSWE benchmark, trailing Anthropic's Opus 4.8 by just 0.7 points. On the GDPval-AA v2 real-world agent evaluation, its score of 1524 matched that of GPT-5.5 (xhigh reasoning).
Other public leaderboards mirror its Artificial Analysis Intelligence Index standing. GLM-5.2 ranked tenth overall on the Agent Arena—securing the top spot among open-weight models—while provisional rankings from BenchLM placed it third out of 124 models with a score of 94.

The Strategic Importance of Surpassing Gemini 3.5 Flash
What makes this resonate isn't one matchup. It's that an open-weight model anyone can download is now trading blows on benchmarks with the latest releases from the frontier's top three — Anthropic, OpenAI, and Google. The model it edged, Gemini 3.5 Flash, is Google's efficiency flagship: built to push past 280 tokens per second and sit in production where premium models are cost-prohibitive.
An open-weight model has now claimed a leading position in this category. The efficiency segment that Gemini 3.5 Flash anchors — long defended by proprietary developers as their competitive moat — has now been matched by an open-weight model that users can download and host locally. Furthermore, GLM-5.2's API pricing—set at $1.40 per million input tokens and $4.40 per million output tokens—offers the lowest cost per task among models of comparable intelligence, positioning it on the Artificial Analysis cost-performance Pareto frontier.
However, some caveats remain. The intelligence index fluctuates based on reasoning-effort configurations and evaluation updates, and some snapshot tests still place Gemini 3.5 Flash ahead. Additionally, a score of 51 remains below the industry's absolute tier: Fable 5 leads with approximately 60, followed by Gemini 3.1 Pro at 57 and Opus 4.8 at 56. GLM-5.2 has not overtaken the highest-performing models, but it has redefined the threshold of efficiency-tier intelligence.

A Coordinated Rise in Open-Weight Performance
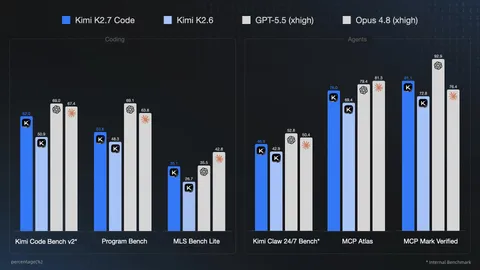
GLM-5.2's ascent is part of a broader trend, as several open-weight models debuted in quick succession. On June 12, Moonshot released Kimi K2.7-Code, which delivered a 21.8% performance increase over K2.6 on its internal coding benchmarks while reducing the reasoning tokens required by 30%. DeepSeek is also expected to release its V4.1 model around the Dragon Boat Festival on June 19. While unofficial, the upcoming release is anticipated to further improve the cost-to-performance ratio of open-source models.
The timing of these releases coincided with geopolitical developments. During the same week, US export controls forced Anthropic to remove Fable 5 and Mythos 5 from the global market. As these frontier models became unavailable internationally, three Chinese open-weight models arrived to fill the benchmark tables within days of one another. This convergence aligns with findings from the Stanford AI Index, which reports that the performance gap between US and Chinese models has closed to 2.7%.
The benchmark results absent at launch have redefined the conversation: a free download now tops the open-weight field on the Artificial Analysis Intelligence Index and has edged Gemini 3.5 Flash. Rather than asking which model is smartest, the entry of open weights into the efficiency frontier raises a sharper question — how long proprietary developers can defend the competitive moat they have relied on.



- Artificial Analysis - GLM-5.2 is the new leading open-weights model on the Artificial Analysis Intelligence Index
- VentureBeat - Z.ai's open-weights GLM-5.2 beats GPT-5.5 on multiple long-horizon coding benchmarks for 1/6th the cost
- MarkTechPost - Z.ai Launches GLM-5.2 With a Usable 1M-Token Context, Two Thinking-Effort Levels, and No Benchmarks at Launch
- DeepLearning.AI - Z.ai's GLM-5 model boasts top open-weights Intelligence Index score
- Stanford HAI - 2026 AI Index Report: Technical Performance